Network Design
Objective
We aim to achieve a design that will specify the networking requirements needed for interoperability and Mainnet in the Prysm Client.
Background Networking is a critical component in building out a client and for communicating and interfacing with other ETH 2.0 clients. The requirements for both interoperability and mainnet are specified in this doc in the specs repository. This document will primarily deal with the three core aspects required for communicating with other clients.
- 1) How peers are discovered
- 2) How messages are propagated through the network(gossip).
- 3) How peers respond to requests from other peers and vice-versa.
Overview
A high level overview of the proposed design. This states the components of the network stack that we need to implement.
- Transport
- Encryption/Identification
- Protocol Negotiation
- Multiplexing
- GossipSub Specification
- Req/Resp Specification
- DiscoveryV5
Transport
For network transport we must be able to support TCP connections (UDP not a requirement). We have to be able to manage inbound and outbound tcp connections. Although not a requirement for mainnet, for interoperability all clients will have to be able to support an IPv4 endpoint. Any listening endpoints must be publically communicable, so Circuit Relays, AutoNat, etc are not applicable.
Current Status in Prysm
Currently we use IPv4 addresses as a default for inbound connections. For interoperability, we can have IPv6 addresses as a default while exposing one IPv4 endpoint as libp2p TCP transport supports listening on multiple addresses simultaneously.
Encryption & Identification
For interoperability we will be using SECIO for securing sessions over transports. These are the parameters required:
- Key agreement: ECDH-P256
- Cipher: AES-128.
- Digest: SHA-256.
- Identity: Secp256k1
In SECIO, channel negotiation begins with a proposal phase, where we exchange information from each peer which declares the ephemeral key generation curve, the cipher for encryption , and the hash algorithm. If the proposal has any of the fields set incorrectly from the specified interoperability requirements stated above, we reject the peer and disconnect with them. Additionally the local peer’s public key, which is used to generate its Peer ID, is also given in the proposal message. This public key is generated using the secp256k1 curve. After performing the key exchange, generating the shared secret and creating the signer and HMAC signer we can initiate a secure channel with the other peer.
Current Status in Prysm
Currently in Prysm we do use SECIO for securing sessions, and a Peer’s identity is generated using the Secp256k1 curve. However we haven’t enforced that the ephemeral key generation curve, cipher for encryption and hash algorithm are the ones that are required for interoperability We would need to strictly define these when peers are making their initial proposal. If they do not adhere to them, we reject and disconnect from those peers.
Protocol Negotiation We must use the multistream-select specification with id /multistream/1.0.0
This is the default multistream multiplexer framework in go-libp2p.
Multiplexing
We need to support the /mplex/6.7.0 multiplexer, which is dynamically decided upon by libp2p at runtime. This is, along with the /yamux/1.0.0 multiplexer are the defaults for the libp2p constructor. See defaults here. No changes are needed to support both of these multiplexers.
GossipSub Specification We currently support the most basic gossip sub approach, but we need to utilize the right parameters as specified in the configuration in the networking specification.
Topic Mapping
The specification outlines specific topics we need to support and their topic names as a standard we must enforce. Both unaggregated and aggregated attestations will go towards the same topic, but we should have the ability in Prysm to process aggregated ones from the network. We need to enforce the max gossip sub message size properly when sanitizing received and sent data.
Req/Resp Specification
Data sent over the wire is enforced as encoded using SSZ for interoperability. We have decided we can support protobuf encoded data if we are communicating between prysm clients, specifically due to efficiency and tooling improvements.
DiscoveryV5 Discv5 is not a hard requirement for our testnets, as we can continue supporting kademlia for now. However it is still required for interoperability, since Discv5 only works for UDP transports, so alternative discovery methods need to be implemented.
Detailed Design
Handshake / Protocol Negotiation
The existing peer negotiation can be mostly reused. The key difference here is that we'll need to maintain a peerstore abstraction where we keep track of the hello messages and potentially continuously update the peerstore abstraction with new values as we learn about them (TODO in a follow up design, as needed).
For a Prysm testnet implementation, we’ll set the fork version to the first 4 bytes of the deposit contract address. This will provide clear separation between testnet deployments.
P2P Messages / Protocol Registration
P2P message topic registration follows the same pattern we have today where the message type is hardcode mapped to the string protocol ID. The topic mapping is used for generic broadcasting implementation.
In the new p2p message paradigm, we will no longer send “announcement” type messages for propagation. Instead, the clients will send the full object for initial propagation. For example, a full block will be sent over GossipSub when it is created/propagated.
There are a few new p2p specific messages (without ssz tags):
package p2p;
syntax = "proto3";
message Hello {
bytes fork_version = 1; // bytes4
bytes finalized_root = 2; // bytes32
uint64 finalized_epoch = 3;
bytes head_root = 4; // bytes32
uint64 head_slot = 5;
}
message Goodbye {
Reason reason = 1; // uint64
enum Reason {
UNKNOWN = 0;
CLIENT_SHUTDOWN = 1;
IRRELEVANT_NETWORK = 2;
GENERIC_ERROR = 3;
reserved 4 to 127;
}
}
message BeaconBlocksRequest {
bytes head_block_root = 1; // bytes32
uint64 head_slot = 2;
uint64 count = 3;
uint64 step = 4;
}
message BeaconBlocksResponse {
repeated eth.BeaconBlock = 1;
}
message RecentBeaconBlocksRequest {
repeated bytes block_roots = 1; // []bytes32, Array of hash tree roots.
}
Encoding Registration In the p2p service, there will be an encoding protocol string mapping to an encoding.
type NetworkEncoding interface {
DecodeTo([]byte, interface{}) error
Encode(interface{}) []byte, error
}
As part of the p2p constructor arguments, the p2p service will know which encoder to use at runtime. As part of the networking specification, it will either be ssz or ssz_snappy, but this design will allow flexibility for other encoding types. Once the encoding has been registered, it can be accessed by the regular sync topic middleware.
func (*p2p) Encoding() NetworkEncoding
The middleware can look up the type, initialize a pointer to an empty object of that type and pass the pointer with the network bytes to the encoding to hydrate the object from bytes by calling p2p.Encoding().DecodeTo(payload, to) where to is a newly initialized pointer. The logic here will look very similar to the logic that we see in RegisterTopic today.
Initial Sync
In this iteration of the networking design, initial synchronizing of a validator with an empty database will be similar to the sync workflow of Ethereum 1.0 where the node syncs from the genesis event. The workflow for initial sync will be as follows:
- Determine the genesis state & block by reading the ETH1 deposit contract logs from a proof-of-work Ethereum node.
- Round-robin batch block sync with N peers from genesis to the last finalized epoch.
- Process batch blocks upon each full epoch received.
- Upon syncing with the last block in the finalized epoch, verify the roots are aligned with the received information on the finalized epoch.
- Continue syncronization with the highest peer using fork choice rules and then resume with regular network syncronization.
The rationale for having step 4 is that we are guaranteed not to have forks or run fork choice rule until we reach the finalized epoch. After that time, we must run fork choice rule to determine the head of the chain.
Note that p2p Sends must wait for a maximum of TTFB_TIMEOUT (time to first byte) for the first response to come across the stream. The client will wait up to RESP_TIMEOUT to receive the full response from the stream.
Open question: How frequently do we need to run fork choice in initial sync, after the finalized epoch? Only at the end of sync, at the end of each epoch, or every block processed?
Answer: Run fork choice at the end of step 5, ensure the roots are as expected.
Handshake Initialization & Hello Tracking
Peers are added to the peerstore from those that are discovered through our discovery protocol. Then Hello requests are sent to all peers which are in our peerstore and we wait for the corresponding hello responses from them. If the response doesn’t arrive in time(ex 5s), we disconnect from those peers. For those that respond with their own corresponding hello responses, we then validate their hello messages, if its invalid we then disconnect with them. If not we begin initial sync as described above.
Since sending and responding to hello requests is a core part of the initial handshake, we will have to use a connection handler, which performs this whenever we dial a peer or vice versa. This ensures that peers that connect to us and are able to propagate messages are only those that are validated according to the protocol
func setupPeerHandShake(h host.Host, helloHandler sync.RPCHandler) {
h.Network().Notify(&inet.NotifyBundle{
ConnectedF: func(net inet.Network, conn inet.Conn) {
}
}
The above describes how we would handle the peer connection in the callback, we would validate each newly added peer using the hello rpc handler. This ensures any application logic stays in the sync package instead of the p2p package
Round-Robin Batch Block Sync
This sync mode requests subsets of the chain to multiple peers, perhaps even with some overlap in the future. The basic flow of this model of requests is to divide the requests evenly in round-robin fashion with peers. An important note to consider for batch syncronization is that a peer must enforce a maximum batch size defined in bytes (REQ_RESP_MAX_SIZE). The requesting client should not exceed this value when determining the batch sizes to request. At the time of writing this document, this value is to be determined. So, we’ll temporarily enforce a max count of 1 epoch worth of blocks. Using the maximum ssz encoded byte size of a block (1.122968 Mb), we can determine the max number of blocks to request to be within the size limit.
For example, if we were to request blocks 10 through 25 from 4 peers:
| Peer # | Batch Block Requests |
|---|---|
| Peer 1 | 10, 14, 18, 22 |
| Peer 2 | 11, 15, 19, 23 |
| Peer 3 | 12, 16, 20, 24 |
| Peer 4 | 13, 17, 21, 25 |
Example Request for Peer 1
{
head_block_root: HashTreeRoot,
start_slot: 10,
count: 4,
step: 4
}
In the event that there is a failure for any subset of the requested range, the remaining blocks will be split across the remaining peers. For example, if peer 3 was disconnected without responding, we would round robin block requests for blocks [12, 24], [16], and [20].
| Peer # | Batch Block Requests |
|---|---|
| Peer 1 | 10, 14, 18, 22 |
| Peer 2 | 11, 15, 19, 23 |
| Peer 3 | 12, 16, 20, 24 (disconnected) |
| Peer 4 | 13, 17, 21, 25 |
| Peer 1 | 12, 24 |
| Peer 2 | 16 |
| Peer 4 | 20 |
Edge case: Empty epoch / empty response (Not needed)
In the event that we request blocks from a peer and receive an empty response, we may assume that this is an error initially and attempt the same request with a different peer. If multiple peers report the same empty response, we can assume this section of the chain contains “skip slots” where no block was produced. While this scenario may be unlikely for extended periods of time in the mainnet deployment, it is very likely in fragile test networks.
Strategy one: retry with multiple other peers
- Request 10, 14, 18, 22 from peer 1
- Receive empty response
- Request 10, 14, 18, 22 from peer 2, and 3
- Process non-empty response from other peers or continue as skip blocks for that epoch
Strategy two: round robin the request to other peers
- Request 10, 14, 18, 22 from peer 1
- Receive empty response
- Request 10, 22 from peer 2
- Request 14 from peer 3
- Request 18 from peer 4
- Process non-empty response from other peers or continue as skip blocks for that epoch
Task: Discuss optimal strategy in design review
Resolution: This section is not needed as clients should respond explicitly with errors.
TODO: How to handle slower peers
Initial Sync UX
The user experience of initial sync should follow a design similar to Parity’s model of displaying interesting metrics as syncronization progresses.
Regular Syncronization
The current regular syncronization design is pretty much a giant for select block that just listens for incoming message announcements from peers, requests the full data, and sends the data over to its corresponding service for handling, such as attestations or blocks. This can be split up, as it is quite unorganized and messy. Current regular syncronization is also tasked with sending and announcing messages to peers in the network, not just receiving. Once again, that responsibility can also be split up for easier testing and readability of the API.
The code will be reorganized into a regular syncronization registry go file where all of the handlers are processed in the main select loop while each handler will exist in its own isolated go file. This pattern will avoid oversized files in the syncronization package.
External RPC (Incoming Request Handling)
The external RPC design implements the “Req/Resp” domain of the network specification. More specifically, the response part. The request part of the domain is covered in the next section, Internal API.
TODO: Consider rate limit requests.
Workflow for receiving an external RPC request:
- A new stream is opened with the appropriate protocol ID.
- Context with timeout is set to TTFB_TIMEOUT (5s).
- Request type is described in the protocol ID and looked up in the request type / protocol mapping.
- Message is read until REQ_RESP_MAX_SIZE or the end of the message, whichever comes first.
- Message payload is decoded using the strategy as indicated by the protocol ID.
- Application hands the message to the appropriate regular sync handler with a reference to the existing stream.
- Handler determines the appropriate response and responds on the already open stream.
- Stream is closed.
If a context has a timeout, the stream should be immediately closed, and a log emitted. Probably at WARN or ERR level.
The method signature for a request handler would be:
func Handler(context.Context, proto.Message, *libp2p.Stream) error
These callback handlers are registered in beacon-chain/sync/handlers/registry.go and each handler must be self contained into its own go file within the handlers package. This isolation of handlers into their own go files keeps the project easier to navigate with tests closer to their implementation and average file lines of code reduced when possible.
Handler: BeaconBlocks /eth2/beacon_chain/req/beacon_blocks/1/{ssz,ssz_snappy}
Accepts a pb.BeaconBlocksRequest message and responds with a pb.BeaconBlocksResponse message. This handler will query the beacon database for blocks and respond as directed by the request query.
Handler: BeaconBlocks /eth2/beacon_chain/req/recent_beacon_blocks/1/{ssz,ssz_snappy}
Accepts a pb.RecentBeaconBlocksRequest and responds with pb.BeaconBlocksResponse message. This handler queries the beacon database for blocks by root and responds with the results.
Handler: Hello /eth2/beacon_chain/req/hello/1/{ssz,ssz_snappy}
Accepts a pb.Handshake and responds with a pb.Handshake. This handler will receive the handshake and compare it against their own. If the handshakes do not align as defined in the network specification, disconnect from the peer after responding with the handshake.
Handler: Goodbye /eth2/beacon_chain/req/goodbye/1/{ssz,ssz_snappy}
Accepts a *pb.Goodbye does not respond. This handler signals to the p2p library to remove said peer from the peerstore. The stream is closed immediately in this handler.
GossipSub
GossipSub as our pubsub library is mostly implemented already with the libp2p GossipSubRouter. The majority of the work here is to ensure parameters are compatible with interoperability and protocols are aligned.
Parameters
| Parameter Name | Description | Value |
|---|---|---|
| D | Topic stable mesh target count | 6 |
| D_low | Topic stable mesh low watermark | 4 |
| D_high | Topic stable mesh high watermark | 12 |
| D_lazy | Gossip target | 6 |
| fanout_ttl | TTL for fanout maps for topics we are not subscribed to but have published to, in seconds | 60 |
| gossip_advertise | Number of windows to gossip about | 3 |
| gossip_history | Number of heartbeat intervals to retain message IDs | 5 |
| heartbeat_internal | Frequency of heartbeat, in seconds | 1 |
Conveniently, these values are the default for libp2p GossipSub. See godoc. However, we should specify these within Prysm to avoid any upstream change breaking interoperability compatibility. Separating these values from hard coded constants will require an upstream PR as it is not configurable. Enabling this functionality can be a bounty and prioritized at P2/P3. At a minimum, we can write a unit test that would fail if any of these config's change since the variables are public.
Propagation: Message Validation
Libp2p’s GossipSub implementation has the concept of topic validators. Registering topic validation would work for the type of validation that we require, however it would also require decoding the same message twice. The trade off is that the topic handler has less responsibility, but at a cost of duplicated efforts.
Proposal 1: Use PubSub.RegisterTopicValidator
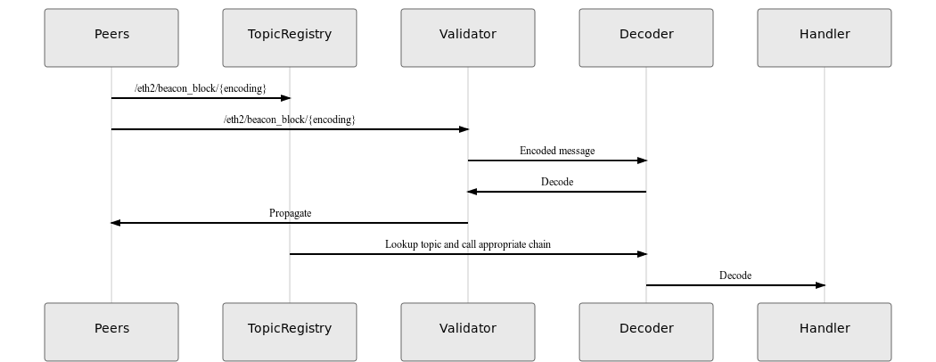
Built in functionality within the existing API will allow for arbitrary validation of incoming messages before automatically propagating to network peers. The benefit here is that the original message is relayed automatically with some knowledge of the originating message. In other words, the library could be clever enough not to propagate the message back to the originating peer.
Proposal 2: Deny all validation in PubSub (selected proposal)
A cost effective way to handle validation of message contents would be to register a validator that rejects everything by always returning “false” and shift this logic into the message handler. The handler will already have a decoded copy of the message and can check the contents for validity before calling Broadcast(msg) to propagate through the network. An alternative would be to registry a chain of adapters like we have in the current implementation.
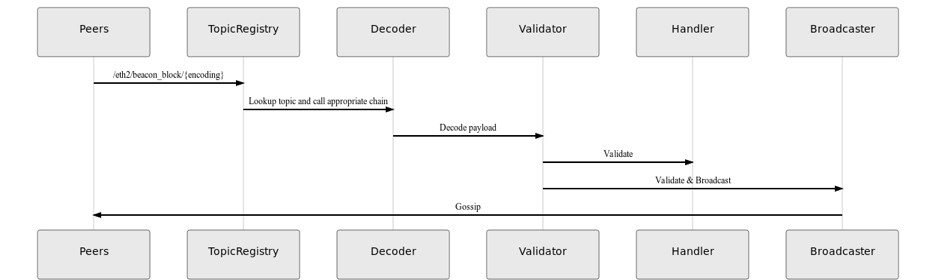
GossipSub Message Handlers
These handlers do not respond like the external RPC handlers. All handlers are expected to
func Handler(context.Context, proto.Message) error
Open question: How does libp2p GossipSub implementation handle re-propagation? Is a message automatically re-propagated through the network or can some validation be checked before relaying the messages to peers?
Handler: /eth2/beacon_block/{ssz,ssz_snappy} Accepts a *pb.BeaconBlock. This topic is used for block propagation. The handler must validate the block signature is valid and immediately forward the message in GossipSub. The block may not process, but the trade off is that blocks can reach the edge of the network faster with the bare minimum validation. The handler will pass the beacon block through the same block processing that we have today.
Handler: /eth2/beacon_attestation/{ssz,ssz_snappy} Accepts a *pb.Attestation. The topic is used for attestation propagation. This handler must validate that the attestation votes on a valid block before forwarding the message through the network. Following that validation, the attestation processing will resume through the existing flow.
Handler: /eth2/voluntary_exit/{ssz,ssz_snappy}
Accepts a *pb.VoluntaryExit. This handler must verify that the exit passes the conditions within process_voluntary_exit before forwarding through the network. Following validation, the request is sent through the operations service for processing.
Handler: /eth2/proposer_slashing/{ssz,ssz_snappy}
Accepts a *pb.ProposerSlashing. This handler must verify the slashing passes the conditions with process_proposer_slashing before forwarding through the network. Following validation, the request is sent through the operations service for processing.
Handler: /eth2/attester_slashing/{ssz,ssz_snappy}
Accepts a *pb.AttesterSlashing. This handler must verify the slashing passes the conditions with process_attester_slashing before forwarding through the network. Following validation, the request is sent through the operations service for processing.
Internal API (Outgoing Request Handling)
The internal API is only concerned with broadcasting and the p2p. Send function should only be called from the regular sync service. Other services should accept a p2p.Broadcaster interface, or at least provide an implementation that prohibits use of Send. The Broadcast method should not change. It continues to accept a generic proto.Message which is used to look up the message topic mapping.
One thing to consider here is what encoding we should broadcast on. This should be controlled by a feature flag to specify encoding selection. The enum flag accepts ssz, ssz_snappy. The default will be ssz as required for interoperability. Ssz_snappy is the required field for mainnet. We must not support multiple encoding at runtime, as specified by the networking specification. Supporting multiple encodings would likely cause undue burden on the network and individual nodes.
Protocol buffers as encoding scheme would be an interesting effort to test in whiteblock framework. Adding another encoding strategy would be trivial to do, but we would need some evidence to support our case for one strategy over another. Networking specification requires SSZ for interoperability, at a minimum.
DiscoveryV5
For discovery we currently use Multicast DNS and Kademlia DHT. DiscV5 is roughly similar to how a kademlia DHT works. However instead of having keys and values stored, Node Records are stored and relayed to other peers. The protocol acts as a database for all live nodes in the network, with each node storing records of a small amount of peers.
An Ethereum Node Record which is defined here, requires at least the IP address of the node and its UDP port. In each of the node records stored, a node’s liveness is periodically validated, and if the node doesn’t respond its record is deleted.
On a positive note the reference implementation is in go over here, we wouldn’t have to implement it, since we can just use this version.
Discovery Communication is authenticated using session keys which are established in the handshake. There are different ways to save node records, either you could utilise an in-memory db for a temporary store or you could spin off a leveldb instance which can be persisted across sessions. For Prysm it would be easier for each node to simply have an in-memory db which stores all the node records, we can look to have a persisted store for mainnet where we can analyse trade offs to this approach.
Listening on a Port
network, err := discv5.ListenUDP(priv *ecdsa.PrivateKey, conn conn, nodeDBPath string, netrestrict *netutil.Netlist)
We listen on a UDP port for incoming messages from other nodes. This returns a network struct though which we can do this.
network.SetFallbackNodes(BootNode)
This would set our provided bootnode as the fallback node since our in-memory database has no peers stored and therefore none to connect with yet, this populates the local table with all the node records stored in the bootnode. We would need to define a specific Topic for beacon nodes to communicate from, otherwise any peer using Discovery5 protocol would be our peer whether they are participating in Ethereum consensus or not. Topic Advertisement and Search would come up in peer discovery for shards where each node will accept topic registrations from other nodes for specific shards and then relay them to other nodes who are searching for specific shards. This is to provide a scalable and reasonably secure solution for sub-networks which cannot afford to have separate bootstrap nodes for each of those subnetworks.
TODO: Add more detail of how to integrate into Prysm.
Fork Choice
Regular sync service will be receiving either blocks or attestations. The block or attestation will get propagated to the block chain service methods ReceiveBlock and ReceiveAttestation. Those two methods call fork choice. From sync service’s point of view, fork choice is a black box. In the example code below:
func (rs *RegularSync) receiveAttestation(msg p2p.Message) error {
resp := msg.Data.(*pb.AttestationResponse)
att := resp.Attestation
// Send att to blockchain service to run fork choice
If err := rs.chainService.ReceiveAttestation(ctx, att); err != nil {..}
// Send att to operation service for inclusion to attestation pool
rs.operationService.IncomingAttFeed().send(att)
func (rs *RegularSync) receiveBlock(msg p2p.Message) error {
resp := msg.Data.(*pb.BlockResponse)
blk := resp.Block
// Send blk to blockchain service to run state transition and fork choice
If err := rs.chainService.ReceiveBlock(ctx, blk); err != nil {..}
Migration strategy
The changes outlined in this document will break the existing workflow for sync, this is unavoidable. The recommended workflow would be to first introduce the API changes, followed by introducing the new protobuf messages, then swapping out the underlying mechanics of each critical component (GossipSub, discovery, initial sync, peer handshakes, etc) without breaking any like-kind client networking in the master branch. In other words, any two clients at the same commit in the master branch should be able to operate a local or distributed network, but there are no backwards compatibility requirements or guarantees.
- Do not break the master branch!
- Avoid any “mega” PRs!
Sync Migration: Initial & Regular Sync
Recommended migration strategy for sync is to refactor regular sync and initial sync package names to contain a deprecated_ prefix. This will allow for new code to be checked into master without causing issues and then the deprecated packages can be removed with the new packages wired up. This will be a breaking change at runtime in the sense that nodes before these changes will not be able to sync with the new protocol, but that is a trade off we can make as version 0.
P2P Migration: Protocol/Topic Mappings
Similar to the sync migration, the existing mapping will be prefixed with deprecated_ until that mapping can be removed and replaced with the new protocols/topics.
Additional Resources
- Networking specification
- Block max ssz encoded size = 1.122968 megabytes excluding body = 368 bytes
16408 (prop slashing) = 6528
18488 (attester slashing) = 8488
1288484 (attestation) = 1085952
161240 (deposit) = 19840
16*112 (voluntaryexit) = 1792